서론
해외 관련 프로젝트가 많은 부서 특성 상 각 국가의 경제 지표, 인구 등 데이터를 빠르게 수집해야 될 때가 참 많습니다.
오픈소스로 공개된 데이터는 워낙 많기에 Pool 자체에는 큰 걱정이 없지만, 그것을 내 목적에 맞게 최대한 효율적으로 가져오거나 가공하는 것은 또 다른 문제입니다.
최근 월드뱅크가 제공하는 데이터를 활용하면서 느낀 불편함을 개선하기 위해 작은 모듈을 만들었습니다. 이에 대한 내용을 소개하고자 본 글을 작성하게 되었습니다.
World Bank Open Data
월드뱅크(World Bank)는 세계은행 그룹 산하의 국제 금융 기관으로, 전 세계의 경제, 사회, 환경 등 다양한 지표를 수집 및 제공하고 있습니다. 이러한 데이터는 경제 발전, 빈곤 감소, 환경 보호 등 다양한 글로벌 이슈를 이해하고 해결하는 데 중요한 역할을 합니다.

월드뱅크의 데이터 목록 일부
월드뱅크는 이 데이터를 World Bank Open Data라는 플랫폼을 통해 데이터를 제공하고 있습니다. 그러나 해당 플랫폼에서 필요한 데이터를 추출하기엔 다소 어렵게 느껴질 수 있습니다. 월드뱅크 데이터는 모든 국가에 대한 다양한 데이터를 제공하고 있기 때문에 데이터의 양이 방대합니다. 이런 플랫폼 내에서 직접 데이터를 조회하고 csv 파일로 다운로드 받는 과정이 쉽지만은 않습니다.
KOSIS와 OPEN API
통계청에서 저와 같이 느꼈는지 월드뱅크의 데이터를 가공하여 제공하고 있습니다.
KOSIS(Korean Statistical Information Service)는 대한민국 통계청이 운영하는 국가 통계 포털로, 국내외 다양한 통계 데이터를 제공하고 있는데요.
KOSIS에 제공되는 대부분의 데이터를 API를 통해 외부에서 활용할 수 있도록 서비스를 제공하고 있습니다. (OPENA API에 대한 내용은 이전 글에 있습니다 → CLICK!)
KOSIS에서 월드뱅크의 데이터는 ‘국제통계’라는 카테고리에서 제공되고 있습니다. 저 개인적으로는 월드뱅크의 플랫폼보다 훨씬 가독성 있다고 느껴집니다만, 이것 역시도 API로 데이터를 바로 호출하는 것보다는 느리고 바로 분석에 활용할 수 없는 형태로 제공 되고 있습니다.
그래서 R의 kosis 패키지를 활용하여 API로 월드뱅크 데이터를 호출하고 필요에 맞게 전처리하는 하나의 모듈을 소개해 드리겠습니다.
본론
API로 데이터를 불러올 것이지만, 어떤 데이터 및 테이블이 필요한지는 알고 있어야 합니다. 따라서 KOSIS 홈페이지에서 테이블을 조회하는 과정은 필수입니다.
작업 순서를 요약하면 아래와 같습니다.

KOSIS에서 필요한 테이블 조회 → 테이블 ID 확인 → R 코드 작성
패키지
본 작업을 수행하기 위해 필요한 몇 가지 패키지를 설치하고 로드하겠습니다.
pacman 패키지를 활용하여 여러 패키지를 한 번에 로드하겠습니다.
# pacman 패키지를 사용하여 필요한 패키지를 설치하고 로드합니다.
library(pacman)
p_load(dplyr, tidyr, googlesheets4, kosis)
R
복사
•
dplyr: 데이터 조작을 위한 패키지로, 데이터를 필터링, 정렬, 요약하는 등의 작업을 수행할 수 있습니다.
•
tidyr: 데이터의 형식을 변환하는 데 사용되는 패키지로, 데이터를 wide format과 long format 간에 변환할 수 있습니다.
•
googlesheets4: 구글 스프레드시트와 연동하여 데이터를 읽고 쓰는 데 사용되는 패키지입니다.
•
kosis: KOSIS Open API를 통해 데이터를 호출하기 위한 패키지입니다.
kosis 패키지는 Seokhoon Joo라는 데이터 사이언스분께서 개발해주셨습니다.
◦
Github:  GitHubseokhoonj - Overview
GitHubseokhoonj - Overview
GitHubseokhoonj - Overview◦
Linkedin: www.linkedin.com
감사합니다.
API
(API 키를 발급하는 절차와 방법은 해당 홈페이지에 상세히 안내 되어 있으니 확인 바랍니다)
kosis.setKey 함수를 활용하여 API키를 설정합니다.
# KOSIS API 키 설정
kosis.setKey("MY API KEY")
R
복사
국가 리스트
국가명을 한국어, 영어, ISO 코드, 대륙을 모두 직접 정리한 리스트가 있습니다.
저의 경우 해당 리스트를 협업에 활용할 것을 염두하여 구글 드라이브에 올려 놓고 호출하는 방식으로 활용했습니다.
월드뱅크 데이터를 호출하고 전처리 하는 데에는 이 테이블이 꼭 필요하지는 않지만, 저처럼 해외 프로젝트가 많은 분들을 위해 테이블을 공유 드립니다.
국가 리스트 테이블
gs4_auth 함수의 email 인수에 자신의 구글 계정을 입력하여 인증을 받습니다.
# googlesheets4 패키지의 gs4_auth 함수를 활용하여 구글 스프레드시트 API에 연결
gs4_auth(email = "ID@email.com")
# 구글 스프레드시트에서 국가 리스트 데이터를 읽어옵니다.
df_country_list <- googlesheets4::read_sheet("https://docs.google.com/spreadsheets/ULR을 입력하세요")
R
복사
월드뱅크 데이터 호출
경제 규모 데이터(DT_2AQ151)
#경제규모 (DT_2AQ151)
df_ecosize1 <- getStatData(orgId = "101",
tblId = "DT_2AQ151",
startPrdDe = "2000",
endPrdDe = "2012",
prdSe = "Y",
objL1 = "ALL",
objL2 = "",
objL3 = "",
objL4 = "",
objL5 = "",
objL6 = "",
objL7 = "",
objL8 = "",
itmID = "")
df_ecosize2 <- getStatData(orgId = "101",
tblId = "DT_2AQ151",
startPrdDe = "2013",
endPrdDe = "2023",
prdSe = "Y",
objL1 = "ALL",
objL2 = "",
objL3 = "",
objL4 = "",
objL5 = "",
objL6 = "",
objL7 = "",
objL8 = "",
itmID = "")
#병합
df_ecosize_origin <- bind_rows(df_ecosize1, df_ecosize2) %>%
arrange(C1_NM, ITM_NM, PRD_DE)
df_ecosize_origin$PRD_DE <- as.integer(df_ecosize_origin$PRD_DE)
df_ecosize_origin$DT <- as.numeric(df_ecosize_origin$DT)
df_ecosize_origin$C1_NM <- as.factor(df_ecosize_origin$C1_NM)
R
복사
모든 국가의 24년치 데이터를 가져오는 것이기 때문에 양이 상당합니다.
KOSIS가 제공하는 API의 용량을 벗어나기 때문에 연도를 나눠 호출한 뒤 병합하는 과정을 거칩니다.
getStatData 함수의 각 인자에 대한 설명은 아래와 같습니다.
•
orgId: 기관 ID → 월드뱅크는 101입니다.
•
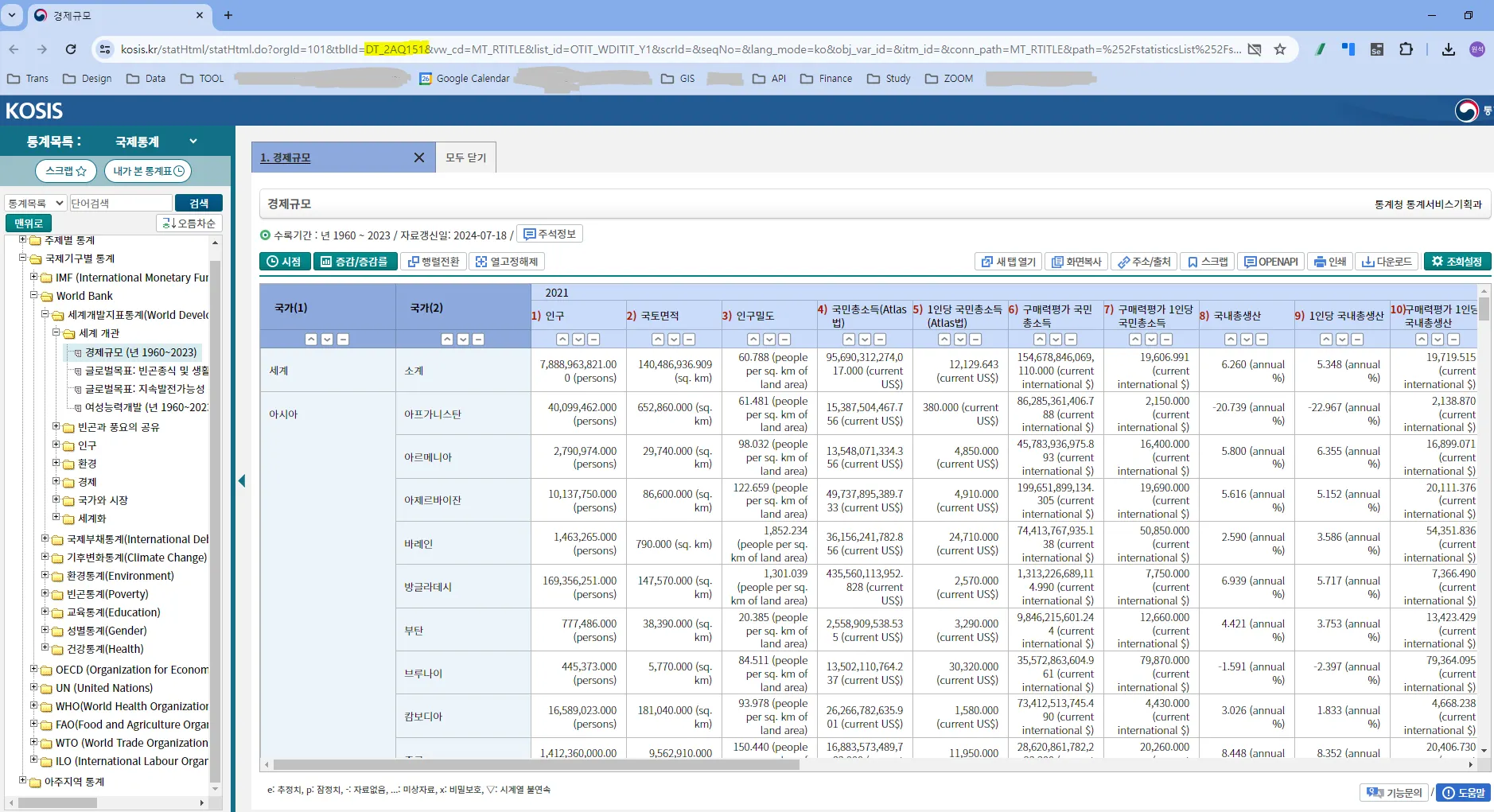
tblId: 테이블 ID
KOSIS에서 조회하고자 하는 테이블을 클릭하면 상단 URL에 tblld= 뒤에 나오는 값을 입력하면 됩니다.
•
prdSe: 기간 설정(년/월 등)
Y, H, Q, M, D, IR이 있습니다. 순서대로 각각 Year(연도), Half(반기), Quarter(분기), Month(월), Day(일), Irregularly(불규칙)입니다.
KOSIS에서 조회했을 때 각 테이블에서 나오는
•
startPrdDe: 시작 연도
포맷: YYYY, YYYYMM(MM:01~12), YYYYHH(HH:01,02), YYYYQQ(QQ:01~04), YYYYMMDD
→ 월드뱅크의 데이터는 대부분 연 단위이기 때문에 YYYY 형태로 작성합니다.
•
endPrdDe: 종료 연도 → startPrdDE와 같습니다.
•
objL1 : “All”이라고 작성합니다. 특정 변수로 필터링하고 싶다면, 해당 변수의 코드화된 변수를 입력하면 됩니다.
예를 들어, 대한민국의 경제 규모만 추출하고 싶으면 아래와 같이 인자의 값을 변경하면 됩니다.
#경제규모 (DT_2AQ151)
df_ecosize1 <- getStatData(orgId = "101",
tblId = "DT_2AQ151",
startPrdDe = "2000",
endPrdDe = "2012",
prdSe = "Y",
objL1 = "100T33J", #인자의 값 변경
objL2 = "",
objL3 = "",
objL4 = "",
objL5 = "",
objL6 = "",
objL7 = "",
objL8 = "",
itmID = "")
df_ecosize2 <- getStatData(orgId = "101",
tblId = "DT_2AQ151",
startPrdDe = "2013",
endPrdDe = "2023",
prdSe = "Y",
objL1 = "100T33J", #인자의 값 변경
objL2 = "",
objL3 = "",
objL4 = "",
objL5 = "",
objL6 = "",
objL7 = "",
objL8 = "",
itmID = "")
R
복사
2개의 데이터프레임을 병합한 데이터셋 df_ecosize_origin는 아래와 같은 형태로 이루어져 있습니다.
API로 호출했을 때 기존 df_ecosize_origin
정말 필요한 변수만 선택한 뒤 tidyr 패키지의 pivot_wider 함수를 활용하여 분석에 용이한 형태로 바꾸겠습니다.
pivot_wider로 변형한 뒤 테이블 형태
원래의 데이터는 각 행이 특정 연도(PRD_DE)의 여러 지표 값들을 포함한 long 포맷으로 되어 있었고, 각 지표는 별도의 열(ITM_NM)로 존재했습니다.
pivot_wider 함수는 이러한 long 포맷 데이터를 wide 포맷으로 변환합니다. 이를 통해 각 지표가 별도의 열로 나타나게 되고, 각 행은 특정 국가(C1_NM)와 연도에 해당하는 모든 지표 값을 포함하게 됩니다. 예를 들어, "1인당 국내총생산", "1인당 국민총소득 (Atlas법)", "구매력평가 1인당 국내총생산" 등은 원래 데이터에서는 여러 행에 걸쳐 있었지만, pivot_wider()를 사용한 후에는 같은 연도 내에서 각 지표가 개별적인 열로 나타나게 되었습니다.
df_ecosize <- df_ecosize_origin %>%
select(C1_NM, PRD_DE, ITM_NM, DT) %>%
pivot_wider(names_from = ITM_NM, values_from = DT)
#불필요한 데이터프레임 삭제
rm(df_ecosize1, df_ecosize2)
R
복사
•
국가 정보 테이블 병합
서두에 잠깐 언급 드린 국가 리스트에 대한 테이블을 병합합니다.
이 과정은 필수는 아닙니다. 그러나 각 국가에 대한 영문명, ISO 코드를 추가할 수 있어 영문 작업 시 도움이 됩니다.
# 경제 데이터와 국가 데이터를 병합
df_ecosize <- df_ecosize %>%
left_join(df_country_list, by = c("C1_NM" = "C1_NM"))
R
복사
연령별 인구(DT_20WBH006, DT_20WBH005)
성별*연령대 인구 비율 테이블(DT_20WBH006) → 남성과 여성 인구 수(DT_20WBH005) → 두 테이블 결합하여 각 성별*연령대의 인구 수 테이블 생성
이번에는 연령별 인구를 구해보겠습니다. 월드뱅크의 데이터는 5세 단위로 연령대의 비율을 제공하고 있습니다. 연령대 별 인구 비율만 제공할 뿐 각 연령대의 인구 수는 따로 제공하고 있지 않습니다. 데이터를 호출한 뒤 각 연령대의 인구 수를 구하여 테이블로 생성해보겠습니다.
•
성별*연령대 인구 비율 테이블(DT_20WBH006) →  KOSIS
KOSIS
•
성별 인구 수 테이블 (DT_20WBH005) → KOSIS
이번에는 호출할 데이터의 용량이 경제규모보다 훨씬 큽니다.
따라서 parallel 패키지의 makeCluster와 parLapply 함수를 사용하여 여러 코어에서 병렬로 데이터를 호출하여 더 빠른 속도로 데이터를 가져오는 방법입니다.
병렬 처리는 여러 작업을 동시에 수행하여 컴퓨터의 처리 속도를 높이는 방법입니다.
마치 피자 가게에서 한 사람이 혼자 피자를 만드는 것보다 여러 명의 직원이 각자 피자 반죽, 소스 바르기, 토핑 올리기, 오븐에 굽기를 분업하여 동시에 피자를 만드는 게 더 빠른 것과 같습니다. R의 parallel 패키지를 사용하면, 우리가 해야 할 작업을 여러 조각으로 나눠서 컴퓨터의 여러 CPU 코어에 분배할 수 있습니다. 예를 들어, 대량의 데이터를 처리할 때, 각 코어가 데이터의 일부를 독립적으로 계산한 후 결과를 합치는 방식으로 시간을 절약할 수 있습니다. 이렇게 하면 작업이 훨씬 더 효율적으로 진행되고, 대량의 데이터를 빠르게 분석할 수 있습니다.
•
detectCores(): 사용 가능한 CPU 코어 수를 반환합니다. 이를 통해 시스템의 코어 수를 파악하여 클러스터를 설정할 수 있습니다.
•
makeCluster(): 지정된 수의 작업자로 구성된 클러스터를 생성합니다. 여기서 num_cores는 클러스터에 사용할 코어의 수를 지정합니다.
두 테이블 중 우선 성별*연령대 인구 비율 테이블(DT_20WBH006)을 호출해보겠습니다.
# 병렬 처리를 위한 라이브러리 로드
library(parallel)
# 병렬 처리를 위한 클러스터 설정
cl <- makeCluster(detectCores()) #가용 cpu 코어 수를 파악하여 코어 수 자동 지정
# 병렬 처리를 위해 필요한 라이브러리와 함수 전달
clusterEvalQ(cl, { library(kosis) })
# 데이터를 가져올 연도 범위 설정
periods <- list(c("2019", "2023"), c("2015", "2018"), c("2011", "2014"),
c("2007", "2010"), c("2003", "2006"), c("2000", "2002"))
# 병렬로 데이터 가져오기
data_list <- parLapply(cl, periods, function(period) {
getStatData(
orgId = "101",
tblId = "DT_20WBH006",
startPrdDe = period[1],
endPrdDe = period[2],
prdSe = "Y",
objL1 = "ALL",
objL2 = "ALL"
)
})
# 클러스터 정지
stopCluster(cl)
# 모든 데이터를 하나의 데이터프레임으로 결합
df_age_pop_ratio_origin <- bind_rows(data_list)
rm(data_list)
R
복사
df_age_pop_ratio_origin 테이블 구조
경제규모 테이블과 마찬가지로 호출한 데이터에서 필요한 변수만 선택한 뒤 pivot_wider 함수를 통해 테이블 구조를 분석에 용이하도록 변형합니다.
# 연령별 인구비율 데이터를 정리
df_age_pop_ratio <- df_age_pop_ratio_origin %>%
select(C1_NM, PRD_DE, C2_NM, DT) %>%
pivot_wider(names_from = C2_NM, values_from = DT)
R
복사
df_age_pop_ratio 테이블 구조
이제 두 번째 테이블인 성별 인구 수 테이블(DT_20WBH005)을 호출하고 테이블 구조를 정리합니다.
# 병렬 처리를 위한 클러스터 설정
cl <- makeCluster(detectCores())
# 병렬 처리를 위해 필요한 라이브러리와 함수 전달
clusterEvalQ(cl, { library(kosis) })
# 데이터를 가져올 연도 범위 설정
periods <- list(c("2019", "2023"), c("2015", "2018"), c("2011", "2014"),
c("2007", "2010"), c("2003", "2006"), c("2000", "2002"))
# 병렬로 데이터 가져오기
data_list <- parLapply(cl, periods, function(period) {
getStatData(
orgId = "101",
tblId = "DT_20WBH005",
startPrdDe = period[1],
endPrdDe = period[2],
prdSe = "Y",
objL1 = "ALL",
objL2 = "ALL"
)
})
# 클러스터 정지
stopCluster(cl)
# 모든 데이터를 하나의 데이터프레임으로 결합
df_age_pop <- bind_rows(data_list)
df_age_pop <- df_age_pop %>%
filter(C2_NM %in% c("전체", "남성", "여성")) %>%
arrange(C1, C2_NM, PRD_DE)
df_age_pop <- df_age_pop %>%
select(C1_NM, PRD_DE, C2_NM, DT) %>%
pivot_wider(names_from = C2_NM, values_from = DT)
R
복사
df_age_pop 테이블 구조
이제 연령대 별 비율(DT_20WBH006)과 성별 인구 수 테이블(DT_20WBH005)을 결합합니다.
5세 단위의 각 연령대의 인구수 변수가 오른쪽에 추가됩니다.
# 연령별 인구비율 데이터와 성별 인구 데이터를 병합
df_age_pop <- df_age_pop_ratio %>%
left_join(df_age_pop, by = c("C1_NM" = "C1_NM", "PRD_DE" = "PRD_DE")) %>%
arrange(C1_NM, PRD_DE)
# 데이터 형식 변환 및 파생 변수 생성
df_age_pop <- df_age_pop %>%
mutate(across(3:39, as.numeric)) %>%
mutate(across(3:19, ~ round(.x * df_age_pop[[37]]/100,0), .names = "{str_remove(col, '\\\\(.*')}")) %>%
mutate(across(20:36, ~ round(.x * df_age_pop[[38]]/100,0), .names = "{str_remove(col, '\\\\(.*')}"))
#연도 변수를 수치형으로 변환
df_age_pop$PRD_DE <- as.integer(df_age_pop$PRD_DE)
R
복사
최종 df_age_pop 테이블 구조
•
mutate(across(3:39, as.numeric))
◦
데이터 프레임의 3번째 열부터 39번째 열까지 모든 열의 데이터를 숫자형(numeric)으로 변환합니다.
◦
이는 데이터가 텍스트 형식으로 저장되어 있을 경우, 연산이 가능하도록 숫자형으로 변환하는 것입니다.
•
mutate(across(3:19, ~ round(.x * df_age_pop[[37]]/100,0), .names = "{str_remove(col, '\\\\(.*')}")) → 남성 인구수 구하기
◦
이 단계에서는 3번째 열부터 19번째 열까지의 값을 특정 계산을 통해 새로운 값을 생성합니다.
◦
각 열의 값을 df_age_pop[[37]]의 값(인구수)과 곱하고 100으로 나누어 비율을 계산한 후, round 함수를 사용하여 반올림합니다. 이 과정이 각 연령별 인구 비율에 대해 실제 인구수를 계산하는 과정입니다.
◦
.names: str_remove를 사용하여 열 이름의 괄호를 제거하여 새로운 열 이름을 설정합니다.
•
mutate(across(20:36, ~ round(.x * df_age_pop[[38]]/100,0), .names = "{str_remove(col, '\\\\(.*')}")) → 여성 인구수 구하기
◦
이 단계에서는 20번째 열부터 36번째 열까지의 값을 특정 계산을 통해 새로운 값을 생성합니다. 마찬가지로 여성 인구수에 각 연령대의 비율을 곱해서 실질적인 인구수를 구하는 과정입니다.
결론
이번 글에서는 KOSIS Open API와 R의 kosis 패키지를 활용하여 월드뱅크 데이터를 효과적으로 수집하고 전처리하는 방법을 소개해 드렸습니다.
글로벌 프로젝트에서 필수적인 경제 지표와 인구 데이터를 신속하게 수집하는 것은 매우 중요합니다. 월드뱅크는 경제, 사회, 환경 등 다양한 분야의 데이터를 제공하지만, 데이터의 방대함과 복잡성 때문에 필요한 데이터를 직접 추출하고 활용하는 데 어려움이 있을 수 있습니다. KOSIS 에서는 이러한 데이터를 좀 더 쉽게 접근할 수 있도록 다양한 통계 데이터를 제공하고 있고, R의 kosis 패키지를 사용하면 KOSIS Open API를 통해 데이터를 직접 호출하고 R 환경에서 쉽게 분석할 수 있습니다. 더불어 방대한 데이터를 API로 호출 할 때 병렬처리하여 시간을 절약할 수 있는 방법을 짧게 소개해드렸습니다.
이 글을 작성하면서 누군가 “야 OOO 대리, 우리 어디 국가에 수출 타진하려고 하는데, 그 국가 경제 상황 어떤지 좀 찾아봐바”와 같은 요청을 받았을 때 1시간 이내로 데이터를 제공이 가능하게 만드는 것에 초점을 맞췄습니다.
제공해드린 코드를 통해 반복적인 데이터 수집 및 전처리 작업을 자동화함으로써, 데이터 기반의 의사결정을 빠르게 내릴 수 있습니다. 이를 통해 글로벌 프로젝트를 진행하는 데이터 과학자나 연구자, 또 무역 쪽 직무의 현직자분들에게 도움이 되면 좋겠습니다.
감사합니다.